ML development lifecycle
A brief walk through of different stages of address a business problem with a machine learning solution.


Machine learning (ML) lifecycle refers to the end-to-end process of developing, deploying, and maintaining machine learning models.
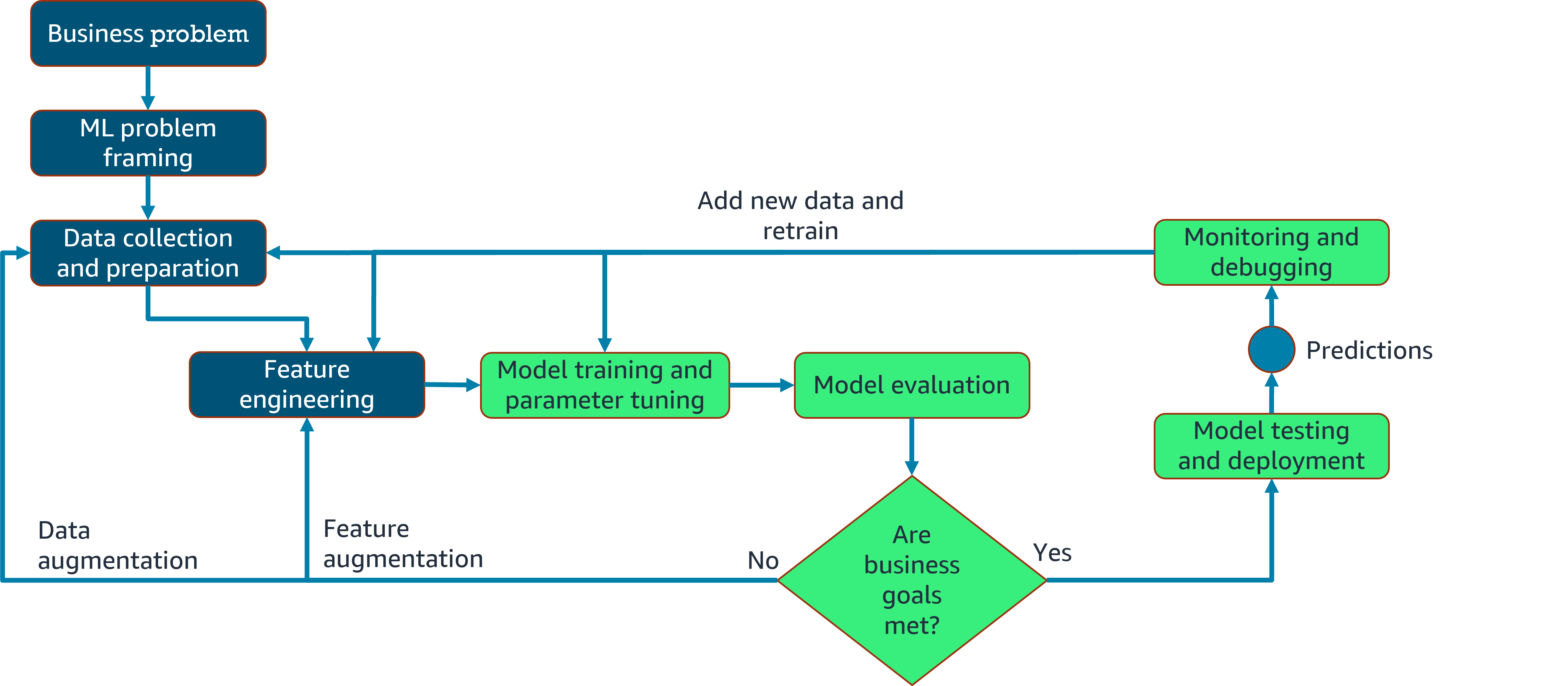
The end-to-end machine learning lifecycle process includes the following phases:
- Business goal identification
- ML problem framing
- Data processing (data collection, data preprocessing, and feature engineering)
- Model development (training, tuning, and evaluation)
- Model deployment (inference and prediction)
- Model monitoring
- Model retraining
The following illustration shows how the phases work together. To learn more, choose each of the numbered markers.
Define business goals
ML starts with a business objective. Business stakeholders define the value, budget, and success criteria. Defining the success criteria or key performance indicators (KPIs) for the ML workload is critical.
ML problem framing
The problem formulation entails articulating the business problem and converting it into a machine learning problem.
The data scientist, data engineers, and ML architects work with the line of business subject matter experts (SMEs) to determine whether it is appropriate to use ML to solve the business problem. In this phase, the teams might work on discovery. They will determine whether they have the adequate data, skills, and so on to successfully deliver the business solution.
Data processing
After they have formulated the problem, the next phase is the data preparation and preprocessing phase.
To train an accurate ML model, developers use data processing to convert data into a usable format.
Data processing steps include data collection and integration, data preprocessing and data visualization, and feature engineering.
Data collection and integration ensures the raw data is in one centrally accessible place. Data preprocessing and data visualization involves transforming raw data into an understandable format. Feature engineering is the process of creating, transforming, extracting, and selecting variables from data.
Model development
Model development consists of model training, tuning, and evaluation.
It is an iterative process that can be performed many times throughout this workflow.
Initially, upon training, the model will not yield the expected results. Therefore, developers will do additional feature engineering and tune the model's hyper-parameters before retraining.
Model evaluation metrics unsatisfactory? Retrain
If the model doesn't meet the business goals, it's necessary to take a second look at the data and features to identify ways to improve the model. Building a model is usually an iterative process. This might also involve adjusting the training hyperparameters.
Model evaluation metrics satisfactory? Deployment
If the results are satisfactory, the model is deployed into production. The model is now ready to make predictions and inferences against the model.
Monitoring and debugging
The model monitoring system ensures the model is maintaining a desired level of performance through early detection and mitigation. Monitoring also helps debug issues and understand the model's behavior.
Continuous improvements
The machine learning lifecycle is an iterative process. The model is continuously improved and refined as new data becomes available or as requirements change. This iterative nature helps ensure that the model remains accurate and relevant over time.